Building tech resilience: 3 steps to tackle outages and safeguard business continuity
When enterprises depend on just a few tech platforms, an outage can disrupt everything. How can organizations prepare? 3 practical steps can help safeguard business continuity.
In today’s world, technology is the nervous system that connects people, businesses, and industries across the globe. Every click, transaction, and communication relies on an intricate web of digital systems that operate in real time. This interconnectedness fuels innovation and efficiency, but it also means that when things go wrong, the ripples travel far and fast. No digital infrastructure is immune to failure.
Tech outages in recent years have underscored this point, affecting both the business and technological communities. In some instances, within hours, critical services—from identity management to authentication portals and mission-critical workloads—came to a standstill. What’s notable is that most of these disruptions weren’t the result of advanced cyberattacks, but rather routine events.
Incidents like these highlight a hard truth: The internet, networks, and sprawling digital infrastructure underpinning our economy are not infallible. The very complexity that enables modern capabilities also multiplies the pathways through which failures can propagate. Nearly every business function (communication, core business services, travel, entertainment, and finance) depends on this digital foundation. When it erodes, business operations can grind to a halt, potentially resulting in millions of dollars in direct and indirect losses per hour.
Each major outage also reveals a deeper vulnerability: the tendency to centralize operations around a single region, provider, or technology stack. This mode of operation can magnify risk, turning minor disruptions into major incidents. Breakdowns act as a reminder of the tangible and intangible costs of single points of failure (financial, operational, and brand) and why many consider diversifying technology architecture.
As organizations increasingly rely on a handful of technology platforms or services, the potential for widespread, cascading disruptions is accelerating. In today’s hyperconnected landscape, resiliency is often defined by foresight, adaptability, and vigilance. Are you proactively identifying potential points of disruption, designing systems that can quickly recover and adapt, and maintaining unwavering vigilance in a constantly evolving digital environment?
Deloitte’s 2025 Global Boardroom survey found that 73% of respondents have increased their emphasis on strategy development and scenario planning in 2025. According to the survey of 739 board members and C-suite executives in 59 countries, the top concerns of respondents include geopolitical and economic volatility (55%), security and cybersecurity (50%), and rapid technological advancements and digital disruption (42%). Focusing on these areas can help leaders enable greater technological resilience.
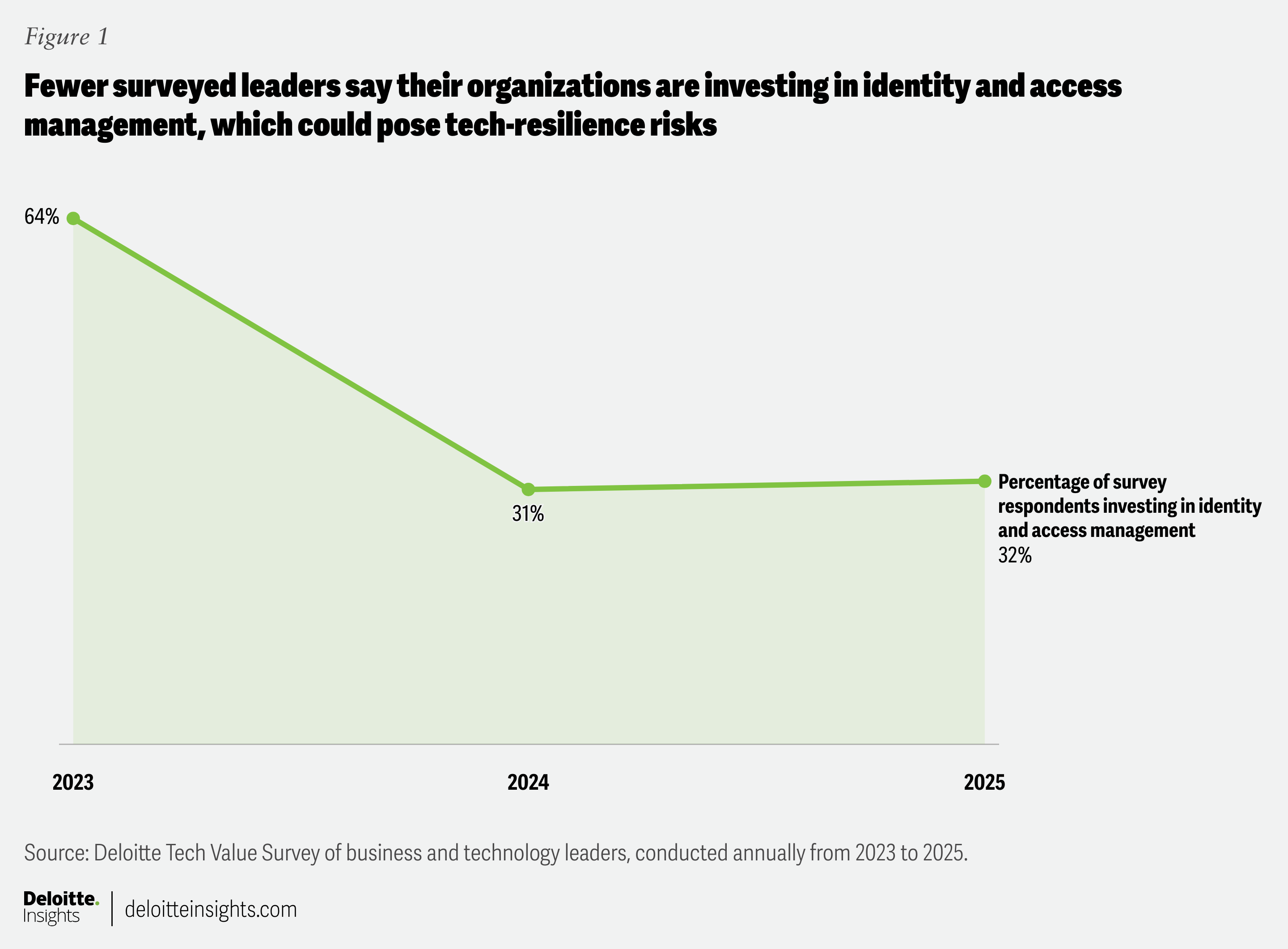
However, Deloitte’s US Tech Value Survey suggests that as technology priorities expand, there’s a risk that future investments in core IT operations and across the tech landscape may be squeezed. Take, for example, identity and access management—one key element for risk management, security, and resilience. The proportion of respondents investing in this area dropped from 64% in 2023 to 31% in 2024 and 32% in 2025 (figure 1).
Core IT investments are important for organizations to recover quickly from adverse events. This relies on clear insight into where vendor concentration exists, a broad understanding of system dependencies across multiple vendors, regular disaster recovery testing and simulations, and intentional design choices throughout the software development life cycle.
Why this matters: A common understanding of tech infrastructure risk
A routine change can lead to a widespread outage, reminding companies just how complex and interconnected digital systems are. A simple update can unexpectedly disrupt critical services, affecting how enterprises serve their customers and run their business.
What can leaders learn from major system outages?
Change control: Even the most routine updates can have big consequences if not managed carefully. If changes aren’t fully tested or if there are intricate dependencies, there typically isn’t a quick way to undo them. A small error can snowball into a much larger problem.
Containing the effects: It’s important to prevent issues in one area from spreading to others. Without strong boundaries and safeguards, a problem in a single system or service can quickly grow, impacting many services and making it harder to recover.
Single points of failure: The vulnerability created by a single point of failure (or SPOF for short) in your architecture can be widespread. When one critical element fails, especially those intended to monitor or connect key services, it can bring down multiple dependent systems. Eliminating or reducing these choke points can be vital to ensuring that operations remain resilient. Concentration risk, especially on the control planes (which direct how systems operate) and management planes (which people use to oversee and administer systems), can compound a single failure into a broader outage impacting many services simultaneously. That shared dependency can create high systemic risk.
Architectural design limitations: Leaders should understand dependencies in how their systems are designed and interconnected. Seemingly minor dependencies can become critical points of failure if redundancy, decentralization, and flexibility aren’t built into the architecture. Designing systems that can detect, respond to, and recover from disruptions can enhance operational resilience.
Service tolerance: Systems need to be able to “bend, not break” when disruptions happen, so that services don’t stop completely. Instead, design solutions to maintain some level of functionality or switch to backups so business operations don’t come to a halt until full recovery.
The new urgency: Why tech resilience can’t wait
In today’s digital economy, the urgency to strengthen technology resilience is becoming more apparent. As organizations grow increasingly dependent on a concentrated set of IT providers and platforms, the risks—from compounding vendor dependencies to IT concentration—are escalating. The consequences of ignoring these risks could be more immediate.
Importantly, organizations should avoid cutting essential features to reduce costs. Too often, disruptions have revealed that even so-called redundant setups may fail if systems can’t switch over smoothly or critical safeguards are absent.
Yet effective resilience strategies call for careful, comprehensive planning and design for every potential point of failure. By considering these three practical steps, organizations may be able to better position themselves to safeguard their operations, reputation, and bottom line.
1. Uncover and eliminate single points of failure and system interdependences
Where feasible, design critical workflows so they do not rely exclusively on a single provider or single service. Avoid single‑vector services (be it a region, zone or multicloud) to move from reliance on a single technology stack to diversified systems, ensuring service availability even if one component fails.
These vulnerabilities could appear anywhere in the tech stack, but let’s look at system endpoints as a common example. System endpoints connect different components—application programming interfaces (APIs), services, databases, and user devices—enabling seamless communication between them. Rather than routing all user access through a single, central point (which can become a chokepoint), regional identity and access management (IAM) endpoints provide location-specific access for users and applications. This allows authentication and authorization locally, closer to where users are working. This approach can not only improve resilience and reduce latency but also keep services available and reliable even if another region experiences an outage. By allowing users to log in and get permissions locally, a regional IAM endpoint can make services faster and more reliable.
But, again, it’s about more than a single point of risk exposure. Technology resilience comes from understanding the interdependencies across multiple levels. Applications run on infrastructure that could be managed in-house (on-premises) or through the cloud—each with its own methods for essential IT operations like configuration management, patching, and system upgrades. Single points of failure can’t be looked at in isolation vis-à-vis an application or a platform team. They should be understood in the context of secondary and tertiary levels of cascading risk that could bring the entire ecosystem under scrutiny. The more layers leaders peel and observe, the more prepared they can become against an impending disruption event. Consider redundant service and journey paths for critical functions.
2. Deploy multiregion and multiprovider fallbacks
When computing workloads are distributed across multiple regional data centers or providers—whether that includes multicloud, hybrid, or on-premises solutions—smart architectural controls can allow services to “run elsewhere” as needed. This goes beyond simple redundancy or automatic failover. It’s about designing infrastructure, so workloads have multiple paths as needs shift. For mission-critical services, consider implementing georedundancy and, where it makes sense financially, strategies like redundant end points, identity management, or fronting strategies to reduce reliance on a single edge provider.
With AI increasing complexity and demand, resilient architectures now need modern, intelligent control planes that can dynamically route workloads. Intelligent or automated control planes need to have strong policy-based governance that enforces clear, rule-based management, especially around access control, which is critical for preventing unauthorized access and security incidents. It’s also important to maintain real-time visibility, with audit trails and observability into automated responses, so organizations can quickly understand and address what's happening across their systems.
Dynamic workload control can be guided by both application and infrastructure tiers, ensuring alignment with business priorities.
3. Conduct game-day scenarios to identify risks and drive observability
Effective preparedness should include developing practical resilience patterns and regularly testing incident response plans, especially for scenarios where the control plane or management plane might be compromised. Run game-day scenarios, including tabletop exercises where services are unreachable, and validate alternate operational procedures.
Proactive network monitoring is the bedrock foundation to detect subtle issues like increases in denial-of-service (DNS) resolution times or gradual rises in API latency for critical endpoints. Yet, modern, proactive resilience also requires leaders to be able to spot concerning combinations—a series of actions that can create a risk choke point where one may not have existed before.1 Case in point: Avoid applications that lack robust caching or don’t support graceful degradation; if a backend database fails, users may lose access to even basic or static features, reducing availability. As another safeguard, consider storing bundled packages of software code in distributed private registries across regions to minimize reliance on external sources during runtime.
To strengthen reliability across modern technology systems, organizations should consider implementing resilience patterns, such as fallback mechanisms and bulkheads, so that other critical functions may still continue to function during a disruption. As an example, if a checkout function on an e-commerce site is temporarily unavailable, customers can still browse products and even place an order using a “buy now” option, limiting business impact.
To help achieve future-ready resilience, organizations should have architectures capable of navigating increasingly complex hybrid networks, applications, and infrastructures.
Is your organization prepared to absorb the true cost of a major outage?
In today’s hyperconnected digital economy, technology forms the backbone of most business processes, relationships, and revenue streams. Disruption isn’t just a distant threat; it’s an inevitable, recurring test of organizational mettle. While much effort goes into reducing the risk of outages, the reality is clear: In a landscape where disruption cannot be completely eliminated, a true hallmark of leadership is proactive readiness.
Observability is a must. Every investment in resilience—whether architectural, operational, or cultural—is a deliberate choice that signals an organization’s commitment to continuity over convenience, to strength over single points of failure. It is how leading organizations can transform lessons from past incidents, not just into remediations, but into foundational changes that harden the business for what’s ahead.
For some organizations, the competitive differentiator won’t be who avoids trouble, but who best absorbs shocks and returns to market faster, wiser, and stronger.
Resilience today is not simply a set of technical controls; it is a currency of digital trust with customers, an enabler of agility when pivoting is required, and an anchor of sustainable growth. It is an asset visible to regulators, investors, and the marketplace—reflecting the depth and seriousness with which leadership embraces uncertainty.
The question isn’t whether another disruptive event will occur; it’s whether your organization will be ready to respond and grow stronger in its wake.
Continue the Conversation
Meet the industry leaders
Chris Thomas
Nitin Gupta
Diana Kearns-Manolatos
by
Chris Thomas
Nitin Gupta
Diana Kearns-Manolatos
The authors would like to thank Deep Upadhyaya for his input and Annalyn Kurtz for her editorial input and support.
Editorial (including production): Annalyn Kurtz, Sayanika Bordoloi, Pubali Dey, and Anu Augustine
Design: Sylvia Chang, Molly Piersol, Jaime Austin, and Harry Wedel
Audience development: Kelly Cherry
Knowledge services: Vanapalli Viswa Teja
Cover image by: Jaime Austin; Adobe Stock
Visit the Deloitte Center for Integrated Research
Access more insights on some of the most complex issues facing businesses today.