AI workloads are surging. What does that mean for computing?
Deloitte analysis explores projected growth in AI computing demand and how business leaders can stay agile
Learn more
As organizations continue to accelerate their artificial intelligence capabilities, data center strategies are evolving rapidly to keep up with the fluctuating computing demands. Deloitte research (detailed in our previous article, “Is your organization’s infrastructure ready for the new hybrid cloud?”) shows a range of infrastructure approaches organizations are exploring based on factors like cost, latency, and hardware needs. The possibilities range from a rush off of the mainframe, to informing new hybrid cloud strategies, to establishing a new market for AI factories. These factories could handle tasks ranging from standard inferencing to high-performance computing at a tremendous scale.1
But for many leaders, building a resilient business and tech infrastructure for the age of AI could pose difficult questions. AI systems depend on large volumes of high-quality data and complex distributed architectures with many interdependent components. Ensuring data availability, integrity, real-time fault detection, robust runtime security, and rapid recovery is important for accurate predictions and effective fault tolerance, especially given the expanded attack surface and the need for low-latency responses.
What’s the right balance among on-premises, cloud, and other high-performance computing (HPC) solutions? How adaptable will the tech infrastructure need to be as AI workloads scale to account for synchronous or asynchronous coordination across orchestration layers? AI consumption and utilization patterns are still largely uncharted territory, potentially making it difficult for enterprises (and operators) to forecast needs and plan with confidence.
To better understand how computing workloads are expected to shift across infrastructure types such as mainframe, cloud, enterprise on premises, edge computing, and emerging technologies in the next 12 months, Deloitte surveyed 120 market operators—including data center providers, energy providers, and distributors—between March and April of 2025 (see methodology). The analysis explores projected changes in computing demand driven by AI workloads, the key factors influencing leaders’ decisions to shift workloads across different infrastructure types, and the steps leaders are taking to address the challenges of scaling their computing infrastructure to meet evolving needs for HPC.
Table of contents
- Demand across tech environments is surging
- How long should you stay on the cloud?
- Tech as a solution to tech challenges
AI is anticipated to drive up computing demand across tech environments
Our survey asked leaders how their computing workload is expected to change in the next 12 months and beyond across tech environments (figure 1).
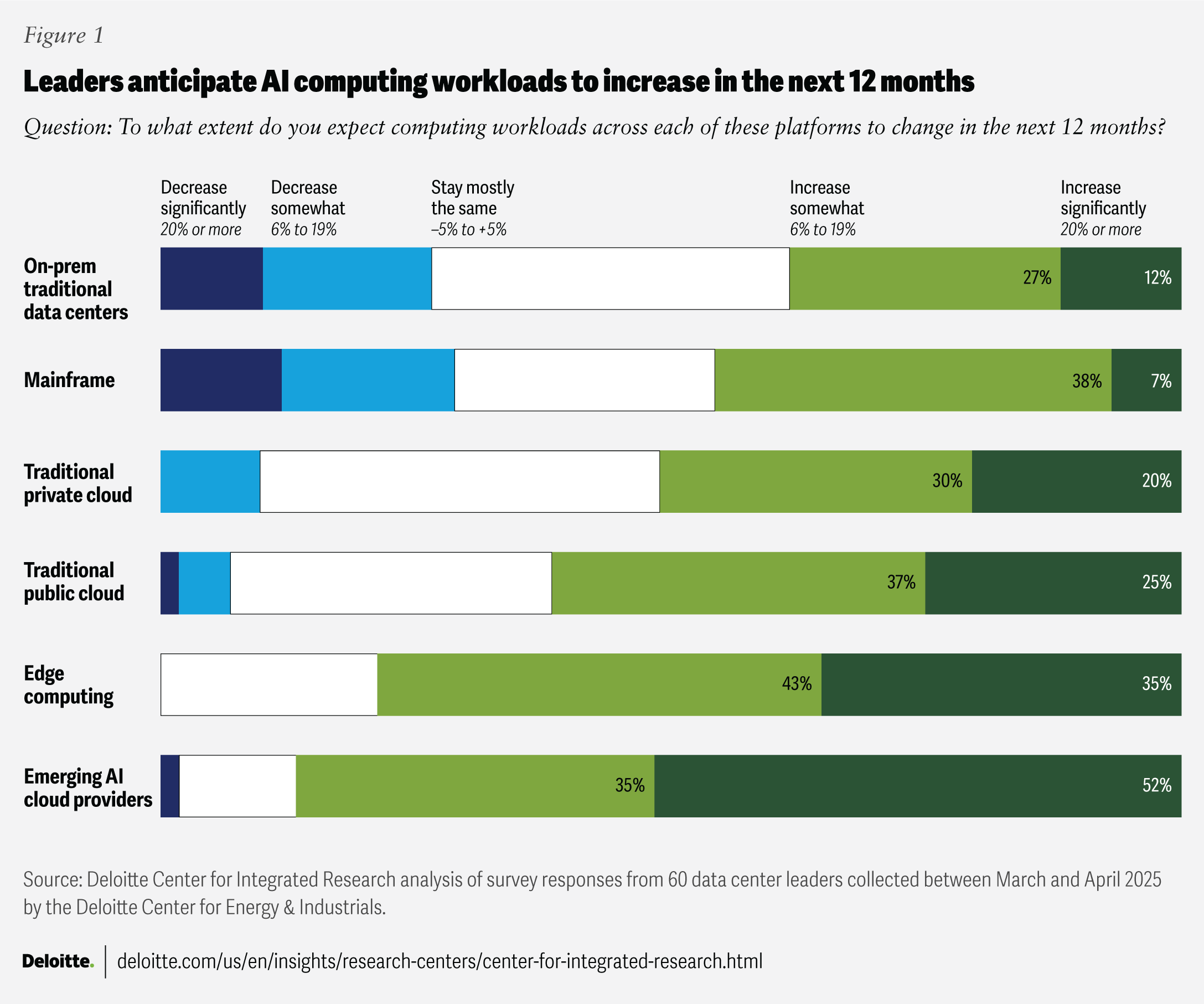
The data shows a clear trend: Respondents expect AI-driven workloads that demand a variety of processing capabilities to increase computing demand across a wide range of platforms. Every tech environment asked about in the survey is expected to see workloads increase by 20% or more in the next 12 months. AI workloads might include pretraining models, improving them through reinforcement learning or other post-training techniques such as chain of thought or reasoning, and then using them for inferencing tasks as AI is deployed at scale, especially agentic AI.
Respondents expect the biggest short-term spikes to come from emerging AI cloud providers (87%) and edge computing platforms (78%), outpacing on-prem data center growth by roughly 10 to 1 and 6 to 1, respectively. Public cloud and private cloud also both show notable anticipated increases. Although mainframe and on-prem data center workloads are also expected to increase in the next year, respondents appear to be reducing their reliance on them as they add capacity elsewhere, or reconfigure existing non-AI on-prem solutions to AI-optimized configurations. Almost a third of respondents say they plan to decrease or significantly decrease mainframe and on-prem workloads in the next 12 months.
While this may correspond with trends Deloitte has discussed elsewhere related to decommissioning mainframes, in the case of traditional data centers, our broader research has shown that organizations are taking multiple approaches to addressing the increased need for computing: reconfiguring existing data centers; reactivating decommissioned data centers; reimagining AI infrastructure with hyperscalers, niche providers, and new entrants; and reviewing GPU (graphic processing unit) and AI token utilization to trigger investments in new solutions.
What might these shifting computing demands mean for business leaders? There may be a need to empower infrastructure leaders to build smarter, more resilient, and efficient environments, while also requiring new approaches to security, governance, and talent management to better navigate disruptions—which many companies may be feeling already. Scaling AI is expected to increase workloads, and some of the potential challenges may be corralling that growth on the right platforms, ensuring that workloads don’t scale where they shouldn’t (like the mainframe), and phasing out legacy tech systems.
Diverse consumption models introduce complexities, which are often addressed by:2
- Designing solutions that run seamlessly across multiple (especially hybrid) cloud environments, often requiring substantial reengineering
- Establishing centralized visibility for real-time fault detection and response across all clouds
- Ensuring reliable, high-speed connectivity between cloud platforms
- Harmonizing security controls and incident response processes across providers
- Enabling secure and efficient data portability between environments
A few of these solutions are driving an engineering-led approach to rethinking control, tooling, and management plans to support the varied consumption patterns. While not specific to a single individual client, Deloitte’s client experience through its hybrid cloud infrastructure offering points to several hybrid models that combine cloud, edge, and on-prem solutions to help create a resilient AI tech backbone.
- Burst first and buy second: Companies can power gen AI copilots using pooled, spot-priced, cloud-based GPUs, deferring major hardware investment until they can prove consistent, high utilization to reduce upfront capital and provide a faster path to testing.
- Selective multicloud: This approach builds on a common foundation where organizations use multiple public or private cloud providers, deploying AI models across several cloud providers. The most critical real-time AI-enabled models can be deployed across clouds, keeping sensitive data and inferencing on-prem on a single platform. This approach limits AI multicloud workloads to manage cost.
- Hybrid cloud-edge: In sectors like autonomous vehicles, health care, and manufacturing, Deloitte practitioners have observed that organizations typically remain connected to the cloud for model training and updates, but the applications and models themselves are decoupled and run locally, usually on relatively advanced local AI processors. This can allow organizations to adapt quickly and push updates flexibly, without disrupting performance at the edge.
- Vertical, air-gapped solutions: In highly regulated sectors like financial services or life sciences, air-gapped on-prem solutions (systems or networks that are physically or logically isolated from unsecured networks like the internet) can offer a secure path for closed-loop AI development and deployment. It’s an approach that appears to be gaining traction among organizations with strict data privacy and security needs and with an emphasis on private cloud modalities, and it may also be used to address increasing sovereign AI requirements.3
Cost is the primary trigger for seeking cloud alternatives—but not for everyone
At the same time, as AI demand grows and scales, several factors appear to be feeding organizational decisions to shift workloads from the cloud, but cost is the top motivator identified in our survey. The majority of respondents (55%) say they plan to incrementally move workloads from the cloud once their data-hosting and computing costs hit a certain threshold. Another 17% cite latency and/or security needs as their main reason for moving off the cloud (figure 2).

However, nearly one-third of respondents (27%) plan to stay on the cloud, even if it costs more. Some organizations may be skeptical that AI workloads will scale enough in the long term to justify a move away from the cloud, but they may be missing the big picture on cost overall. Beyond data storage and computing cost (typically measured in GPUs and central processing units [CPUs]), organizations should also account for the cost of model usage and the increased cost that comes from inferencing,4 typically measured using AI tokens.
As organizations are learning more and models are evolving, some leaders may have seen that understanding cost dynamics could benefit from a thoughtful approach to financial operations across the entire data and model life cycle. This could go beyond cloud cost, including the cost of data hosting, networking, inferencing, and latency for HPC across hybrid infrastructures. As solutions become more advanced, leaders should consider being nimble in making decisions that give them flexibility in a fast-moving environment where new options are emerging for data hosting, computing, networking, and inferencing.
Across the life cycle of building, operating, and running AI infrastructure, technology resiliency can involve:
- Modular design: Composable components that isolate failures and enable rapid recovery or replacement
- Robust versioning: Strategies to prevent data loss during development and training
- Continuous monitoring: Ongoing health checks and anomaly detection across hardware, software, and data pipelines
- Proactive security: Real-time threat detection, incident response, and regular patching to address evolving cyber risks
- Dynamic scalability: Ability to scale resources seamlessly to meet unexpected spikes in demand or workload changes
- Latency and performance monitoring: Solutions that track the speed and throughput of compute to ensure that latency requirements are met relative to the speed of compute required
- Financial operations transformation: A rework of cloud financial operations to incorporate increases in data calls and model usage specific to cloud machine learning
Technology resilience may depend on systems being able to operate amid both expected shifts and sudden disruptions. It should be about more than business continuity, also involving proactive planning for infrastructure changes.
AI magnifies that challenge for some. These systems don’t just run on tech—they’re embedded in complex digital ecosystems. As their role in the organization grows, so does the need for infrastructure that can keep pace.
Leaders can potentially strengthen hybrid cloud machine learning agility by taking some deliberate steps to prepare. Consider the following.
- Decide where the organization wants its data gravity to be. As the organization scales AI use, deciding where data “lives”—securely, accessibly, and with high performance—becomes an important decision. The location of your most queried data effectively becomes the center of gravity for AI applications and agents, regardless of where inferencing happens. While an AI application may do a good job pulling data from multiple internal and external sources, data sprawl can add to complexity and cost. Be intentional about what stays on public and private clouds, what moves onto it, and what may need to be moved off of it to recalibrate your data center of gravity. Factor in privacy, latency, workflow, and sovereignty requirements to determine if data should be centralized in a private cloud, traditional on-prem, or private AI infrastructure options. Factor also in connectivity, interoperability, and latency needs that may require more open solutions, such as a public cloud.
- Design for interoperable networks that build on and off ramps for models to be hosted where they are now and where they may be needed in the future. Organizations working to build resilient hybrid infrastructure models that adapt to future needs might be better served by designing for interoperability from the start. While it was initially believed that training foundation models and running production AI models within applications that conduct inferencing would not require the same level of data input, networking, and processing power, scaled AI applications have shown they too require a thoughtful approach to networking so that data storage is not a drain on the system and high performance can be maintained across many users.5
Some companies are building on-prem GPU farms for both training and inference needs. Others are using models that are application programming interface–enabled and require no on-prem infrastructure. The answer could be to use a combination—for instance, an open-source or open-weight large language model on-prem that could be fine-tuned on a private cluster.
Rather than locking into one setup, infrastructure should allow models to be hosted and workloads to move based on context—across systems, users, and even multi-agent operations—while maintaining the right guardrails and access controls. Consider investing in dedicated hardware, such as large clusters, as needs are understood. A pragmatic, incremental approach, leveraging both cloud and alternatives, could better deliver the agility, cost-efficiency, and control grounded in real-world demands required for high-performance computing that AI workloads typically require.
Some organizations plan to stay on the cloud—perhaps longer than they should
While there are many economic considerations that should go into calculating the total cost of ownership across AI infrastructure (e.g., CPUs, GPUs, networking, AI token costs, etc.), for organizations concerned about high cloud computing costs, our survey asked them at what point they’d consider moving workloads off of the cloud and buying their own GPU rack (figure 3).
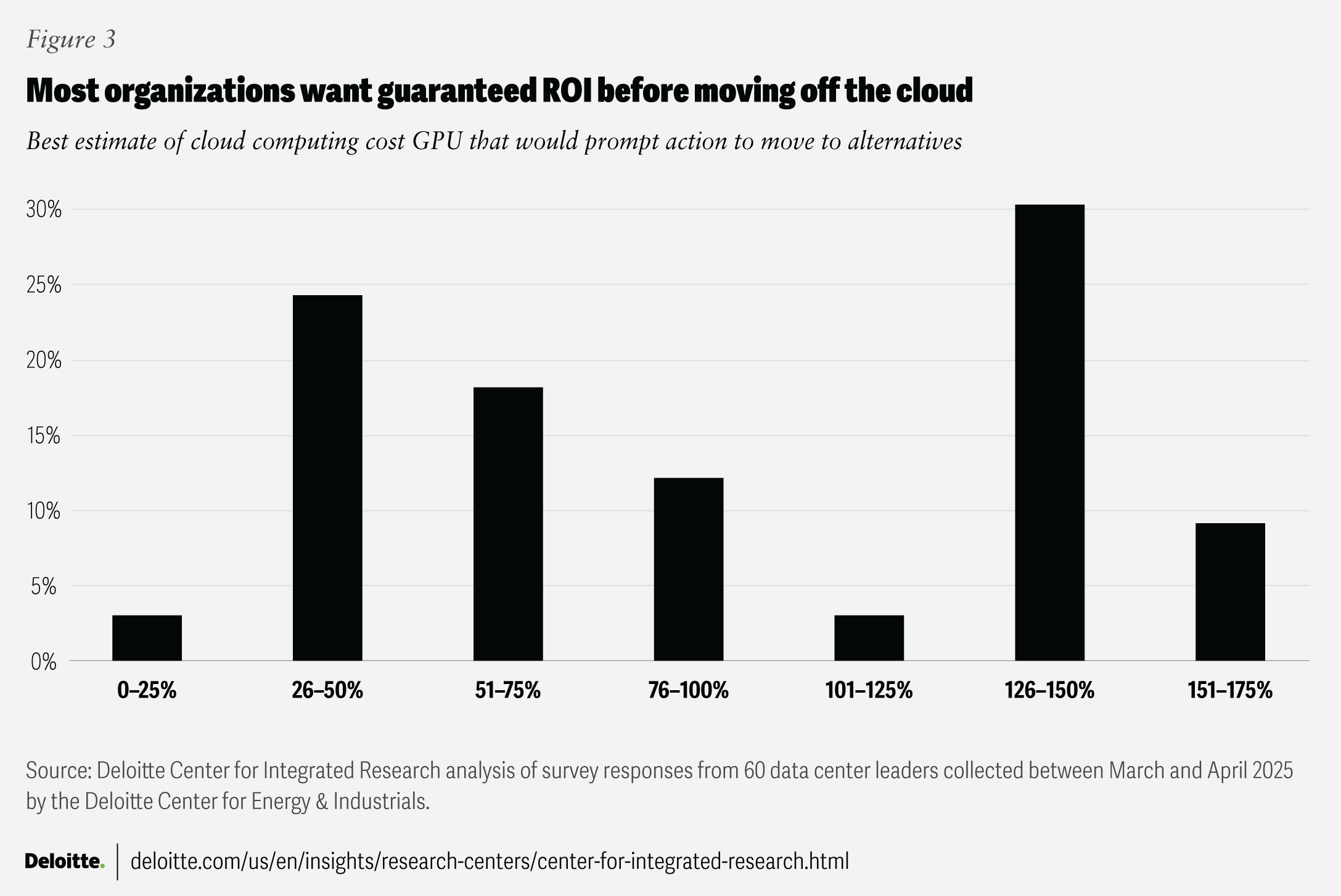
The largest share of respondents (30%) say they won’t consider moving workloads off the cloud until cloud costs reach 1.5 times what they’d pay for an alternative—waiting until a GPU rack can save them 50% right out of the gate. In other words, they appear to want a guaranteed day-one return on investment before making a switch. This is potentially concerning given that this measure is only one of several inputs to the total cost of ownership across a mature AI tech stack.6
Cloud solutions offer on-demand access through subscription models, possibly reducing upfront risks and enabling organizations to quickly scale to meet fluctuating demand. This can include access to the latest hardware, such as specialized GPUs for AI, machine learning, high-performance computing, and visualization tasks. Cloud solutions can also help simplify experimentation by making it easy to spin up GPU clusters for development, testing, and training.
But at a certain stage, this approach could come with a cost. Risk-averse organizations may use the cloud for pilot inferencing to avoid capital expenditure obligations and maintain a low operational expenditure experimentation model. These organizations, however, may end up carrying the cost of a high cloud bill longer than necessary and miss the opportunity to invest in high-performance infrastructure that could drive differentiation and competitiveness with AI business capabilities.
Our survey suggests that some organizations may be moving ahead early based on GPU indicators, while others may be better equipped to account for the total cost of ownership. Twenty-four percent of respondents say they plan to move off the cloud when the cost reaches 25% to 50% of the relative cost of alternatives.
Given that cost is the top driver for most organizations surveyed, leaders can consider a few important actions.
- Get a centralized view of your enterprise infrastructure footprint. Some organizations may struggle with siloed infrastructures, making it difficult to get a centralized view of data-hosting costs, computing, networking, inferencing, and API calls across the enterprise. A comprehensive view of your enterprise architecture, combined with projections on where you expect costs to increase based on your organization’s AI vision, can help guide more intentional technology investment decisions. For example, Deloitte worked with a financial company’s global head of infrastructure and operations to address this challenge with a dashboard view. They worked across the business to map workload utilization, tech stack requirements, security needs, hosting environments, and application architecture to establish a baseline across the company’s computing footprint to guide future business decisions.
- Account for new inference cost dynamics. In addition to CPU and GPU usage, managing the cost of inference can also be factored by optimizing AI token usage. AI tokens break down data into tokens that serve as the currency for AI models and applications at scale. Financial operations and infrastructure strategy teams can better understand the total cost of ownership of their AI investments by bringing together computing and inference usage metrics.
Organizations may need to approach AI infrastructure differently based on their scale and needs. At one end of the spectrum, API-only approaches allow access to high-performance computing infrastructures without direct investment, though leaders should still account for model usage costs. A more moderate approach can involve investing in hybrid AI infrastructures that bring together a combination of traditional on-prem, public/private cloud, edge, neo clouds, or dedicated AI clusters that the organization owns and operates. These configurations may vary based on current infrastructure and future requirements.
Some large-scale organizations are building their own AI factories—data centers optimized for processing AI workloads. While these require a larger up-front investment, purpose-built hardware and models lower lifetime usage costs and may even open up new revenue streams.7 For example, Deloitte’s Center for Technology, Media, and Telecommunications reported that 15 global telecoms in over a dozen countries brought new AI factories online in 2024, with more following suit. Whether an organization is experimenting with AI or is operating at scale, infrastructure decisions should align with workload and performance needs.
Tech innovation may be a solution for tech challenges
As enterprises navigate the evolving demands across their tech estate, data center operators acknowledge the challenges. According to our survey, respondents’ two biggest concerns as compute demand grows are power and grid capacity constraints (70%) and cyber or physical security (63%).8
As the computing paradigm evolves, 78% of respondents suggest that technological innovation could also be the answer.
Several possible factors can reshape how organizations consume GPUs to help manage these supply and demand dynamics.
- Evolving data residency and privacy laws may require sensitive data to stay within specific geographies, pushing organizations toward on-prem or hybrid models.
- Falling GPU hardware costs and better utilization through virtualization or sharing can make on-prem deployments more attractive.
- Growth in AI inferencing for reasoning models may not need all GPU clusters to be centralized in the way that training does. Smaller GPU servers, spread across multiple locations—even hundreds or thousands of kilometers apart—may be able to handle these workloads. Since the servers are smaller, they could fit into existing data centers without major upgrades like liquid cooling, different power supplies, or thicker floors required by larger GPU clusters.
- Emerging threats or breaches could prompt organizations to limit or change usage for sensitive workloads.
- Shortages of skilled IT staff could accelerate alternative deployment models.
- Rise of edge needs (AVs or smart cities, for example) could increase demand for GPUs closer to data sources, changing the deployment strategy.
- Advances in workload mobility and orchestration tools could make it easier to move GPU workloads across different environments.
While approaches like managing CPU and GPU usage and using smaller models can be beneficial, for some organizations, they may have limited impact. Eventually, organizations may have to consider whether a cloud-centric approach gives them the resilience they need or whether they need to invest in managing their data, network, and infrastructure with new alternatives based on their inferencing needs as well as their computing needs.
As enterprises scale AI workloads, finding the right balance between innovation and risk management could be essential. Long-term success could depend on deep workload visibility, high-quality data, and strong security protocols. Leaders who prioritize these capabilities may be better positioned to avoid costly missteps and unlock the full potential of AI.
Methodology
The Deloitte Research Center for Energy & Industrials conducted a survey in April 2025 to identify US data center and power company challenges, opportunities, and strategies, and to benchmark their infrastructure development. The survey’s 120 respondents include 60 data center executives and 60 power company executives and included questions on infrastructure buildout challenges, resource mix to meet future energy consumption, workforce issues, AI workload planning, drivers of load growth, and investment priorities. The Center for Integrated Research focused on the 60 data center respondents and analyzed how these leaders expected computing demand to increase or decrease in the next 12 months based on AI workloads, what might cause them to move workloads from the cloud, and specific cost triggers for that move based on a specific cost per GPU inflection point.
Continue the Conversation
Meet the industry leaders
Chris Thomas
Nikhil Roychowdhury
Diana Kearns-Manolatos
BY
Chris Thomas
Diana Kearns-Manolatos
The authors would like to thank Nikhil Roychowdhury and Brenna Sniderman for their insights.
We also extend our gratitude to the core research team members: Duncan Stewart, Ahmed Alibage, Akash Chaterji, Carolyn Amon, David Levin, Kate Hardin, and Saurabh Bansode.
Additionally, we thank Corrie Commisso, Edith Martinez, Ireen Jose, Lisa Beauchamp, Negina Rood, Nicole Bostock, Prodyut Ranjan Borah, and Saurabh Rijhwani for their support in production and marketing.
Cover image by: Natalie Pfaff
Visit the Deloitte Center for Integrated Research
Access more insights on some of the most complex issues facing businesses today.