Is your organization’s infrastructure ready for the new hybrid cloud?
Rising cloud costs, data sovereignty, and modernization needs may be hindering AI’s potential. These five insights can help leaders rethink hybrid cloud solutions for the AI age.
Learn more
As artificial intelligence adoption accelerates, some organizations are looking to modernize tech systems that could be holding them back from realizing the potential innovation and optimization benefits these technologies offer.1 For those that are already using AI cloud services, either from hyperscalers or emerging AI pure-play neoclouds, costs can become challenging as AI workloads scale. Meanwhile, issues like varying latency needs,2 data readiness,3 security,4 and sovereignty5 can become more pressing. At the same time, new hardware and private AI infrastructure options are coming into the market,6 creating pressure for organizations to adapt.
To help AI thrive across the enterprise, leaders may need to rethink their cloud strategies. This evolution may not be easy, but AI infrastructure pioneers can adopt new, more flexible hybrid cloud approaches that can help with decisions related to where data and foundation models should be stored; where training and inference should occur; and how to scale across solutions, including on-premises, public/private cloud, edge computing, and an emerging class of private AI infrastructure. Since the computing needs for training and inferencing/agentic workloads are different from traditional AI structures and carry different infrastructure requirements, organizations may need to transform their data and infrastructure to meet these new demands.
Our analysis, based on interviews with 20 Deloitte US leaders on the future of AI infrastructure and conversations with more than 60 global client technology leaders across industries, conducted between February and May 2025, surfaced five insights that can help guide future AI infrastructure decisions.
1. Hybrid models can help manage large-scale AI workloads and public cloud affordability.
Public cloud costs can become a budget-breaking exercise as workloads scale, prompting organizations to consider hybrid options. Financial operations and usage scaling are known challenges in cloud computing, but given the data storage and computing power needed for modern-day AI, companies may come to that inflection point sooner than they think.
2. AI hardware and operating model innovations for faster, cheaper, and smarter processing can be game changers.
Advanced hardware like neural processing units, tensor processing units, and AI-embedded personal computers (PCs), along with operating model innovations, including a mixture of experts and custom AI architecture, can help enterprises more effectively process large data sets and execute complex AI tasks in real time while enhancing energy and cost efficiencies.7
3. Edge and high-performance computing can help meet data security and variable latency needs.
As AI-enabled hardware comes online, it is expected to drive some organizations to edge computing (where computing and data storage are brought closer to the sources of data). In highly complex and uncertain environments, more advanced, high-speed, and interoperable networking capabilities will likely be needed. This could be especially relevant as new agentic AI solutions that may not require a high volume of graphics processing units (GPUs) come online.
4. A choose-your-own-adventure approach for hybrid cloud infrastructure can allow for better customization.
Private AI infrastructure is taking center stage, though adoption is still a choose-your-own-adventure model with various paths for organizations. While some organizations are expected to stay on the cloud, others are in the early stages of implementing their private AI infrastructure strategies. For some, investing in lower-cost units could still give them enough computing power and latency for slowly training or inferencing large language models with under 200 billion parameters.8 On the other hand, organizations launching full-stack AI digital products or AI-as-a-factory service models may need to invest more heavily in rack scale solutions that can cost millions to tens of millions of dollars.
5. Data center 2.0 approaches can aid energy efficiency, cost savings, and AI-native upgrades.
Some hyperscalers, telecommunications companies, and private data centers are modernizing their infrastructures for AI, prioritizing efficient and sustainable energy sources, cost savings, and GPU accessibility. Strategies can include expanding GPU compute with additional hardware such as boxes, trays, and specialized chips; locating computing resources near the energy source; and utilizing advanced liquid cooling techniques. These considerations apply to both providers and organizations upgrading their own data centers, some of which are expected to require running a dense stack of machines with dedicated power and cooling solutions. In other words, meeting the demands of advanced chips and hardware may require more than just an upgrade. True transformation may be needed across all paths.
As organizations work to optimize their AI infrastructure, tech leaders will likely need to navigate each of these five forces. The following sections will explore each insight in detail and discuss how leaders can use them to help innovate and adapt their technology infrastructure to thrive in an AI-driven future.
Hybrid models for managing large-scale AI workloads and public cloud affordability
According to the interviews conducted for this research, many AI projects start in the cloud, based on the organization’s existing public and private footprint. However, as AI projects scale, there will likely be an inflection point where the public cloud may become too expensive, and purchasing dedicated AI infrastructure may become more economical than renting cloud computing capacity.
Financial discipline can help organizations avoid entering into two- to three-year fixed vendor agreements. Instead, organizations can start in the cloud and monitor for when the cost of cloud computing for a given workload reaches a preset threshold, which our interviewees suggested could be 60% to 70% of the total cost of buying systems (for example, GPU-powered boxes with four to eight modules). When that happens, it may be time to think about redistributing AI workloads.
Leaders can better understand their computing capacity needs by tracking data and model-hosting requirements (in gigabytes) relative to the number of transactions per second that one GPU can support. As more data is stored and more teams inference simultaneously, it can take longer to process the same workload. A drag on performance could indicate it may be time to invest in dedicated GPU-powered boxes.
In addition, leaders should continue to assess business needs and return on investment objectives to determine if the cloud meets all functionality needs, such as token ingestion speeds, network capacity, latency, and security requirements. Building first and expecting the business need to then find you along the way may not be sustainable. Instead, consider the business need first and then build for it.
As cloud usage reaches a value inflection point, alternative approaches such as edge computing and high-performance computing can also be considered.
Game-changing AI hardware and operating model innovations for faster, cheaper, and smarter processing
With new AI chips launching every few months,9 enterprises should consider factoring chip innovation into their infrastructure decisions. More advanced chips and specialized AI processors could impact the calculus of processing power and energy consumption across AI workloads. Larger data sets can now be processed on smarter and more powerful chips that enhance energy efficiency, reducing operational costs and environmental impact (figure 1).10
Figure 1
AI processing chip innovations are impacting the AI infrastructure landscape
${optionalText}
Chief information officers can now develop teams of engineers to chunk data, manage models, and oversee load management. Advancements like neural processing units can enable organizations to accelerate smaller AI workloads with higher performance and more energy efficiency by mimicking a human brain’s neural network. This allows enterprises to shift sensitive AI applications away from the cloud and process AI locally.25
To handle complex computational workloads, it’s important for diverse hardware to connect and coordinate. For example, companies such as HPE are working to integrate chips into the hardware stack, whether it be private cloud AI or an AI factory, helping to enable organizations to then build an application layer on top of the hardware for a complete full-stack solution.26
The pace of innovation among tech vendors is happening quickly. In a span of only six months, Google launched the Ironwood chip, and A4 and A4X virtual machines.27 And Intel28 launched processors such as Core Ultra (Series 2), Core Ultra 200V, Core Ultra 200HX and H Series, and more.
To further differentiate in the market, some chipmakers and hardware manufacturers are creating their own software solutions to help simplify complex chip-level tasks and improve adaptability, which can allow them to add more models quickly and easily in the future (figure 2).29 These software advancements complement hardware and chip innovations by fully leveraging the enhanced processing power and bandwidth of modern hardware.
Figure 2
Emerging software and security innovations leverage modern hardware advances
${optionalText}
While new innovations like these can offer advantages, organizations may want to avoid the hype. An organization may not need the latest chip for another two years, for example, with further efficiency gains available before buying systems with smaller GPU-powered boxes or large trays inside dedicated AI racks. Given that these trays can generally come with GPUs, CPUs, and special chips connecting the hardware for AI training and inference,46 organizations could see impacts to cooling and power strategies.
Edge and high-performance computing for meeting data security and variable latency needs
As organizations evaluate whether technology upgrades are needed, they can consider whether edge computing may be the right solution to enhance existing systems.
According to research from Fortune Business Insights, the global AI edge computing market is expected to grow to US$267 billion by 2032, from US$27 billion in 2024.47 According to a 2024 Deloitte survey, while few US organizations invested in edge computing that year, those who did reported a 13-percentage-point jump in their belief that their organization is gaining ROI from the investment between 2023 and 2024.48
Our interviews suggest that the move toward edge computing may be due to two drivers: AI tasks that require either low latency, low storage, low compute, or high data security; and a new class of AI devices where AI capabilities are embedded into the device hardware (for example, mobile phones, laptops, wearables, cameras, drones, humanoid robots, and more). While intelligent edge devices have been available for some time, one difference is the ability to now process tasks directly on the device and without an internet connection.
An example of hybrid cloud and edge AI deployment is Walmart, which uses a “triplet model.” The model integrates two public cloud platforms with Walmart’s private cloud, distributed across its facilities in the east, west, and central regions of the United States. Complementing these regional clouds are 10,000 edge cloud nodes within its stores and clubs, enabling scalable, low-latency data processing and AI inferencing directly at the point of customer interaction. Together, they can allow for both the scale and responsiveness required to deliver high-quality, personalized experiences. Another example is Netflix,49 which uses a public cloud for content management and user data tracking, while its private cloud-based content delivery network delivers video to customers, offering reduced latency. Jaguar TCS Racing uses multiple cloud and AI technologies to analyze real-time car performance data, enabling engineers and drivers to make live decisions.50
Deloitte’s 2024 Tech, Media, and Telecommunications Predictions report51 projected that 30% of all personal computers sold in 2024 would have local AI-processing capabilities, and that nearly half would have these capabilities in 2025. And according to the 2025 edition of the report,52 AI-enabled PCs could account for more than 40% of shipments in 2026. Given the chip innovations previously discussed, AI chips will likely feature in a variety of devices, including autonomous cars and industrial robots.
Advancements can make it easier for enterprises to build edge networks incrementally, rather than basing network development on any single inflection point.
As organizations update laptops and mobile devices, AI is expected to increasingly be available on corporate devices, making this a slow-burn issue for organizations to consider as part of their long-term infrastructure innovation, and device management and security strategies. Similarly, physical AI capabilities like mobile humanoid robots introduce additional physical safety and power requirements, as well as the ability to interface with virtual simulations that could require considerable infrastructure reimagination. Mobile devices may also impact existing bring-your-own-device policies and networks as employees upgrade personal devices used for work that may have AI on them, and vice versa.
Additionally, after more than a decade of creating data lakes to structure data for traditional AI, those interviewed suggest that federated data approaches can help enable AI agents powered by underlying generative models.53 As the volume and complexity of the data being harnessed by generative AI models continues to increase exponentially, the cost savings derived from employing a federated data storage approach, where specific data is accessed when needed for analysis, versus a centralized data lake (often at significant cost), becomes even more significant. At the same time, security vulnerabilities inherent in moving and centralizing data are mitigated. Some companies use a novel ontological layer that maps disparate data back to complex real-world phenomena.54 This can help drive insights from the data, and its myriad out-of-the-box connectors enable it to connect to and make sense of federated data wherever it resides.55 This type of AI platform can make it easy to develop and leverage agentic workflows to maximize the insights that can be derived from the data. Generally speaking, federated models can also help prep, clean, and categorize data to improve data quality and integrity. This can be particularly important in a complex and uncertain world, as organizations navigate changing geopolitical landscapes and work to verify the security and reliability of sensitive information.
Federated models are expected to require detailed access controls based on user roles to manage AI agents that can think and create across connected systems. For example, a customer information system might use an application programming interface to send a request to the system to verify the requester’s permissions. The AI agent could then decipher the prompt, identify the requester’s role, and make an API call if the user is authorized. Additionally, incorporating human-in-the-loop oversight helps provide a safeguard against potential AI biases, can enhance decision-making, and can allow for continuous improvement of AI models.
While edge computing may be a viable option for low-compute AI workloads, on the other end of the spectrum, high-performance computing is an option some organizations are exploring for compute-intensive AI workloads. Organizations pursuing deep research or genomic sequencing, for example, may require unprecedented computing speed and dense arrays of GPUs that can be used for modeling and simulations.
For those looking to take that plunge, a spectrum of options is emerging.
Choose-your-own-adventure for hybrid cloud infrastructure
AI infrastructure investments can be a bit of a choose-your-own-adventure experience. There are many paths, each with different outcomes based on different AI strategies. At the extremes, organizations may choose to invest in new enterprise gen AI hardware or choose to stay on the cloud no matter what (figure 3).
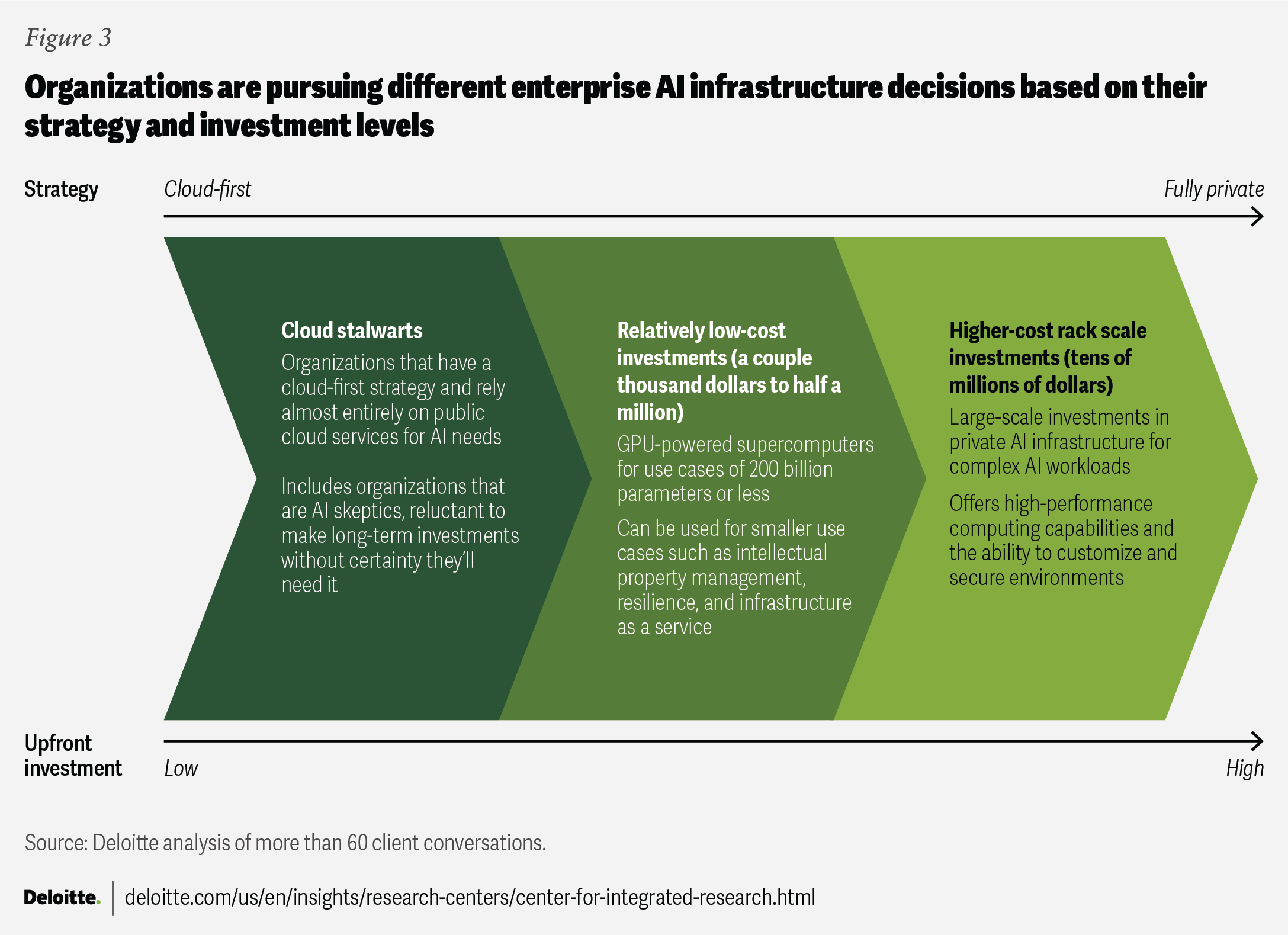
Enterprise AI infrastructure build-out across this spectrum is happening in real time, with organizations making different choices based on their overall priorities.
Cloud stalwarts: Some organizations Deloitte spoke with said they want their AI infrastructure to be cloud-first and that they may not plan to move off the cloud, even in five years. This could be because if AI infrastructure is a spectrum, they can rely on the public cloud. While they may be AI skeptics, reluctant to make long-term investments without certainty they’ll need it, this road could be inadvisable for managing the risks and opportunities of AI. At some point, cloud stalwart strategies will likely need to be augmented with alternatives like edge computing, neural processing units, or a similar option. These alternatives may need to be brought in, for example, to distribute training and especially inference from the public cloud to edge devices that an organization needs to own and operate.
Relatively low-cost investments: Organizations can choose to deploy non–rack scale solutions that meet computing and latency needs for smaller use cases such as intellectual property (IP) management, resilience, and infrastructure as service offerings. Although some may be opting for desktop AI solutions valued at a few thousand dollars, more are choosing solutions such as a GPU-powered supercomputers that are a few hundred thousand dollars.56 While about 90% cheaper than rack scale solutions, these supercomputers require a smaller up-front investment but are still able to handle AI training of up to about 200 billion parameters,57 allowing companies to train small language models, up to the lower end of large language models (LLMs).
One company in the Europe, the Middle East, and Africa (EMEA) region that Deloitte spoke with, for example, plans to purchase such a box to create a country, language, and organization-specific module to house their own data and run a private LLM. They decided on this approach based on national AI sovereignty rules and IP concerns. While it might have been faster to execute training in the cloud, the company is most concerned with protecting its own IP to make sure others can’t access it and ensure that their LLM is not influenced by others’ data.58
In another conversation, we learned that other companies are focused on low-cost infrastructure investments, which is the case for one Asian telecommunications company, which plans to invest in its own AI hardware in an effort to confirm 100% resilience and business continuity for mission-critical, real-time operations for users.59 The company says it recognizes that its wireless customers will have limited capacity with the AI chips in their phones, creating an opportunity for the telecom to provide AI support for these devices.
To achieve this, the company noted that they plan to use private cloud processors on-site for certain applications that require both business continuity and support for users’ edge devices. Their envisioned workflow includes phones capturing images or audio, preprocessing the captured media with a neural processing unit, and then sending smaller, curated files elsewhere for further processing. The processed data can then be sent back to the end user, all with acceptable latency. To help meet the bandwidth and processing needs for the mobile user, the company is investing in multiple smaller data centers, with two or three boxes or racks per center to enhance bandwidth and to scale to meet future demands for latency and resilience.
Higher-cost (tens of millions of dollars) rack scale investments: As enterprise use cases scale and additional power is needed for inferencing, some organizations appear to have graduated to even larger GPU-based racks that are better suited to giant-scale AI and high-performance computing applications.
One electronics manufacturer in Asia said in an interview with Deloitte that their research and development center, for example, has invested in new AI infrastructure based on a strategy to deliver sovereign, local language, full-stack applications both internally and to its clients based on future IP breakthroughs.60 They say they’re investing in the large-scale computing infrastructure they need to compete with tech, media, and telecommunications hyperscalers as they use gen AI to test and take new digital products to market.
A Middle East financial technology company told Deloitte it wants to develop its own AI chatbots for social media marketing.61 They plan to create an AI character to talk to social media users and promote their services, so they can own their avatar without the risk of proprietary IP running in the cloud.
Another use case where an investment in a larger private infrastructure footprint may be valid is among enterprises investing in smart robotics infrastructure. For example, one company in Asia has a large robotics business and needed generative AI computing capabilities that would allow it to run models at a latency of 2 milliseconds or less.62 The company noted that it invested in its own gen AI inference box, which could be nearby, controlling inferences made by the robots onsite.
Long-term infrastructure strategies could also contribute to organizations investing in private AI infrastructure. For example, one EMEA bank63 told Deloitte they are committed to building gen AI capabilities into their products and infrastructure both today and well into the future to be competitive. They noted that financial information security and portability laws are expected to restrict moving data outside of the country and that locally owned and operated data centers will be required to own and house the data.64 To help prepare for this, the bank is investing in thousands of advanced AI chips for its data center to meet current and future needs, especially for other businesses in the region that they plan to support with AI factory services and inferencing as a service capability.
As global organizations decide which of these options are right for them, many of the large-scale private AI infrastructure options will likely need to be housed in a data center with the requisite cooling (likely to require liquid cooling by the 2026 version of AI chip racks), power, connectivity, and more. Many companies already have data centers, and as they purchase gen AI solutions, they are often adding one or two expensive racks to their existing data center. Some are exploring refurbishing old data centers, while others are building new ones from the ground up as fresh solutions.
Data center 2.0 approaches for energy efficiency, cost savings, and AI-native upgrades
AI compute demand is expected to increase by as much as 100 times as enterprises deploy AI agents,65 putting increased pressure on existing data centers. Deloitte’s 2025 Tech Trends report66 advises that, instead of scrambling for limited GPUs available in the market, it may be more efficient for organizations to understand where they are ready for AI and adopt a tailored hardware strategy. Without oversight, GPU consumption can escalate, which can lead to high costs and inefficiencies. Financial controls with monthly usage reports, and dynamic workload allocation among GPUs, could help manage consumption, maintaining a balance between performance and cost-effectiveness.
Based on our interviews, several GPU consumption management approaches are emerging based on upfront investment and deployment speed, including reactivating decommissioned data centers, reconfiguring existing data centers, reviewing existing GPU utilization, and reimagining data center strategies with hyperscalers, niche providers, and new entrants (figure 4).
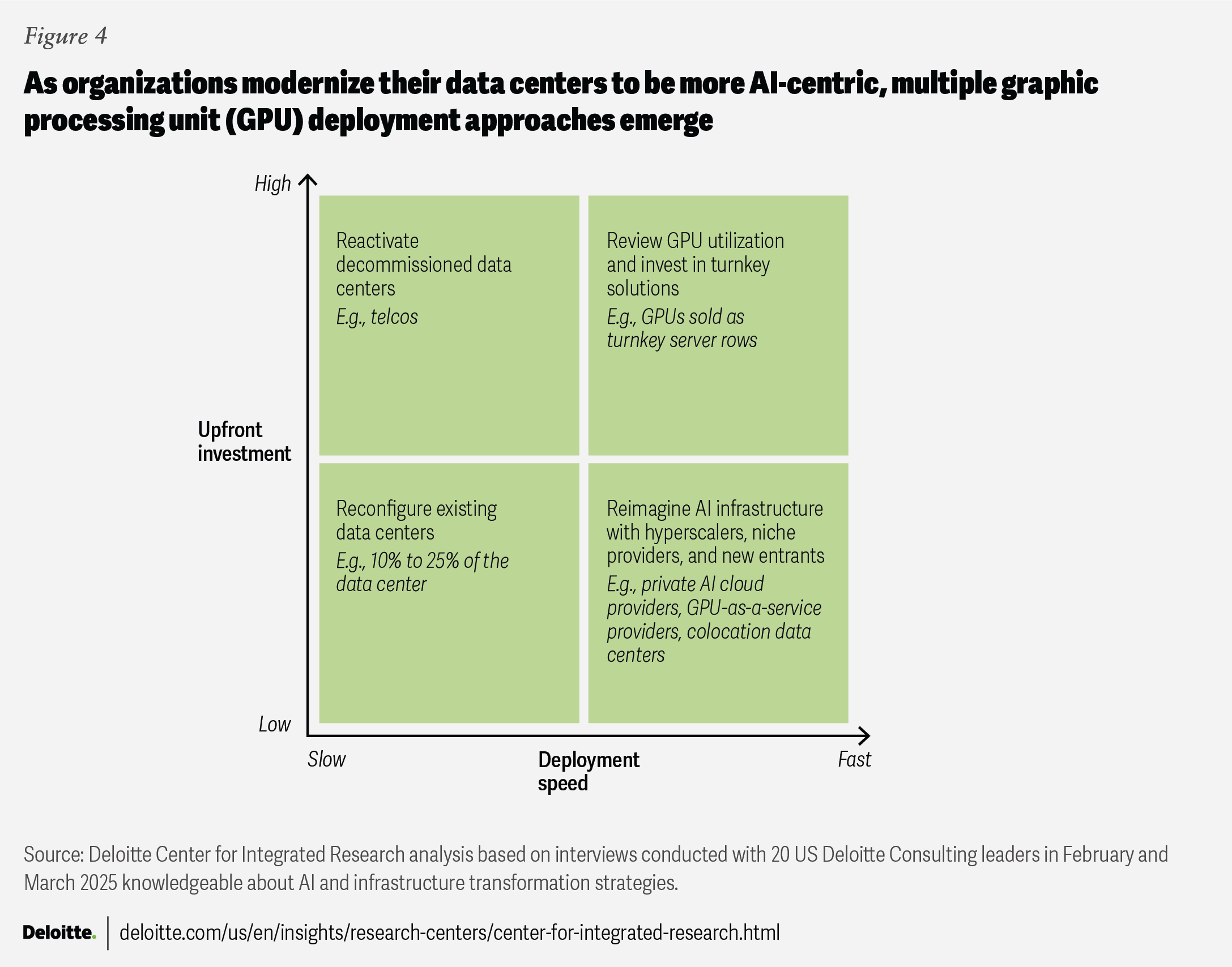
Reactivate decommissioned data centers to build capacity: high upfront investment, slow deployment. Hyperscalers, telecommunications companies,67 and other organizations are often bringing older data centers back online to meet demand. This can involve an assessment of power and utility needs to handle GPU usage. An organization may consider working with a provider to move workloads back to previously decommissioned data centers, especially if they need more control over data or infrastructure or better cost optimization.
Reconfigure existing data centers: low upfront investment, slow deployment. Rather than spending millions of dollars replacing entire data centers, organizations could allocate a portion of their data center to bring in AI-dedicated hardware and scale gradually. This approach can offer high control and customization to scale infrastructure at their own time, pace, and budget.
Review existing utilization and the need for GPUs sold as turnkey rows of servers to reduce set-up time and complexity: high upfront investment, fast deployment. While an organization may not be ready to invest in a row of preconfigured and ready-to-use GPU boxes or trays at the start of their AI journey, this option may start to make sense when they reach a point where using cloud services becomes too costly or when they need faster processing. For example, Lockheed Martin, a global security and aerospace company, implemented turnkey solutions in their AI factory to accelerate the development and integration of AI. It helped enable their developers to securely access high-performance computing resources, reducing setup time from weeks to minutes and training times from weeks to days.68
Reimagine AI infrastructure with hyperscalers, niche providers, and new entrants: low up-front investment, fast deployment. While reimagining AI infrastructure may seem to require a high initial cost, new GPU-as-a-service providers or colocation data centers offering ready-to-use infrastructure can likely save upfront costs and bring greater speed to deployment. A new class of AI infrastructure providers has entered the market: neoclouds, or pure-play AI cloud providers; colocation providers; and companies that are making rack scale solutions. Many of these companies provide private hardware (from a small GPU-powered box to a large tray with multiple server racks, each with four to eight GPUs) and cooling capacity, which are designed to work efficiently for both training and inferencing workloads.69 For instance, Aston Martin Aramco partnered with CoreWeave to relocate Aston Martin’s on-premises computing infrastructure to a new, large-scale cloud computing environment to unlock AI-accelerated engineering opportunities.70 Genesis Therapeutics also partnered with Lambda to accelerate its AI-based drug discoveries using a scalable, high-performance AI cloud, without long-term contracts or infrastructure overhead.71
New data center upgrades to support AI workloads and higher processing at the edge may require leaders to innovate their approach to edge computing networks. One way is to use fine-tuned models to access idle GPU or microprocessor unit capacity on the end-user device. This can help optimize edge compute and storage capacity and enhance security. In an environment with thousands of GPUs working together, all demanding efficient utilization, it is expected to be important to have a lossless, hyper-connected network that offers searchable, federated learning capabilities. For example, IOPS (input/output operations per second), which measures data retrieval speed, needs to be high for AI solutions to retrieve data quickly from storage hardware.72 Networking options can help to transfer data efficiently from storage to servers, where GPUs process it.73
A common challenge: The growing power demands of data centers
Energy efficiency is expected to be important for those data center 2.0 enterprise strategies where tens or hundreds of racks are running at the same time. Power consumption is expected to increase significantly, with average power density anticipated to reach 50 kW per rack by 2027.74 By 2030, there are predictions for even higher power densities, as well as increased weight per rack.75
These demands could impact power grids across the United States, Ireland, Singapore, and elsewhere,76 as they struggle to meet the needs of the growing number of AI data centers. However, there are ways to address these impacts.
- Liquid cooling: Liquid cooling involves integrating cooling systems directly into the racks, helping to reduce power usage by as much as 90% compared to air-based cooling methods.77 Emerging techniques like direct-to-chip liquid cooling, immersion cooling, and in-row cooling use nonconducting liquids to better absorb heat and reduce energy consumption.78 For example, immersion cooling of GPU servers, in some cases, can reduce energy consumption by 50% compared to traditional air cooling. The containerized design can enable faster setup and allows data centers to scale their operations easily.79
- Public-private energy partnerships: Data centers may face challenges due to their high power consumption. Additionally, power generation and transmission equipment is experiencing supply chain issues, with deliveries for some critical components extending between two and four years.80 By collaborating with the private sector, government could help confirm access to essential equipment and a reliable and varied power supply, including options like sustainable energy, traditional sources, or even nuclear energy.
- Using renewable energy sources with sustainability as a key focus: As dedicated AI data centers continue to require more electricity, some organizations are pursuing cleaner energy sources to meet the demand. For example, Google’s new data center in Arizona is expected to use over 400 megawatts of clean energy from solar panels, wind turbines, and battery storage systems.81 Similarly, Nokia has partnered with atNorth, a Nordic colocation provider, to build a sustainable data center in Finland that runs on renewable energy and recycles waste heat to lower its carbon footprint.82 Nuclear energy is also becoming an increasingly viable option for providing high energy density while producing minimal greenhouse gas emissions.83
- Building data center capacity near energy sources to help minimize transmission loss: High energy demands are driving partnerships between utilities and tech companies to colocate data centers with power generation facilities. Solutions like small modular nuclear reactors and microreactors can be built closer to data centers given their smaller size and modular design, which can help minimize transmission losses.84
When choosing an AI infrastructure strategy or making data center transformations, it can be helpful to write down clearly what your architecture considerations are for different workloads, and the reference patterns that you can give to your larger organization. For example, if you want low upfront costs and quicker deployment, consider as-a-service players. If you can accommodate the high upfront costs and want more control and customization, you can choose to build a private cloud. This can help provide a clear path and pattern to infrastructure decisions and can help your organization utilize resources effectively.
A hybrid approach for an AI-first future
As leaders develop their AI infrastructure strategies, they should consider their hybrid cloud strategies, balancing factors like costs, latency, performance, and data sovereignty. Hybrid solutions can become more important as cloud workloads scale, while edge AI and high-performance computing can mitigate latency and security concerns. Advancements in AI hardware and software could enhance energy efficiency and cost-effectiveness, and data centers could be redesigned to prioritize AI operations. By applying these insights, leaders can work to transform their infrastructure to accommodate the future of enterprise AI.
Continue the Conversation
Meet the industry leaders
Chris Thomas
Rahul Bajpai
Akash Tayal
Byron Cheng
Diana Kearns-Manolatos
Duncan Stewart
BY
Chris Thomas
Akash Tayal
Duncan Stewart
Diana Kearns-Manolatos
Iram Parveen
The authors would like to thank those who invested their time and expertise into the development of this research.
This includes Byron Cheng and Rahul Bajpai, who played an important role in defining the scope of the research and providing key insights on the topic.
We would also like to thank Arpan Tiwari, Baris Sarer, Blair Nicodemus, Franz Gilbert, Ganesh Seetharaman, Matt Kalman, Matthew Shannon, Myke Miller, Nicholas Merizzi, Oniel Cross, Ram Ravi, Rohit Tandon, Shawn Lund, Shomic Saha, and Stephen Brown who graciously agreed to be interviewed and lend their critical expertise on the topic. We also thank Abdul Mohammad Hannan for his input on the draft.
We are also grateful to the marketing team, including Anushka Bose, Edith Martinez, Ireen Jose, Kaneez Fizza, Lisa Beauchamp, and Saurabh Rijhwani, for their guidance and leadership on extending the global reach of these insights.
Special thanks to the Deloitte Insights team, including Corrie Commisso for her editorial input; Jim Slatton and Rahul Bodiga for their creative vision; and Aditi Rao, Blythe Hurley, and Prodyut Borah for their production support.
Cover image by: Rahul Bodiga