The AI infrastructure reckoning: Optimizing compute strategy in the age of inference economics
As AI moves from proof of concept to production-scale deployment, enterprises are discovering their existing infrastructure may be misaligned with the tech’s unique demands
When generative artificial intelligence exploded on the scene, businesses got busy dreaming up next-generation products and services. Today, AI has grown up. But as it moves from proof of concept to production-scale deployment, enterprises are discovering their existing infrastructure strategies aren’t designed for AI’s demands.
Recurring AI workloads mean near-constant inference, which is the act of using an AI model in real-world processes. When using a cloud-based AI service, this can lead to frequent API hits and escalating costs, prompting some organizations to rethink the compute resources used to run AI workloads. But the problem isn’t just cost; it’s data sovereignty, latency requirements, intellectual property protection, and resilience. The solution isn’t simply moving workloads from cloud to on-premises or vice versa. Instead, it’s building infrastructure that leverages the right compute platform for each workload.
While exploring AI-optimized infrastructure, organizations will find that advances in chipsets, networking, and workload orchestration can address critical needs across the enterprise. Organizations that act now, addressing both infrastructure modernization and workforce readiness, can define the competitive landscape of the computation renaissance ahead.
The inference economics wake-up call
The mathematics of AI consumption is forcing enterprises to recalculate their infrastructure at unprecedented speed. While inference costs have plummeted, dropping 280-fold over the last two years,1 enterprises are experiencing explosive growth in overall AI spending.2 The reason is straightforward: Usage, in the form of inference, has dramatically outpaced cost reduction.
Large language model (LLM) tools based on application program interfaces (APIs) work for proof-of-concept projects but become cost-prohibitive when deployed across enterprise operations.3 Some enterprises are starting to see monthly bills for AI use in the tens of millions of dollars. The biggest cost contributor is agentic AI, which involves continuous inference, which can send token costs spiraling.
Why organizations are rethinking compute
Rising bills are forcing organizations to reconsider where and how they deploy AI workloads, but there are other factors.
Cost management: Organizations are hitting a tipping point where on-premises deployment may become more economical than cloud services for consistent, high-volume workloads. This may happen when cloud costs begin to exceed 60% to 70% of the total cost of acquiring equivalent on-premises systems, making capital investment more attractive than operational expenses for predictable AI workloads.4
Data sovereignty: Regulatory requirements and geopolitical concerns are driving some enterprises to repatriate computing services, with organizations reluctant to depend entirely on service providers outside their local jurisdiction for critical data-processing and AI capabilities. This trend is particularly pronounced outside the United States, where sovereign AI initiatives are accelerating infrastructure investment.5
Latency sensitivity: Real-time AI workloads demand proximity to data sources, especially in manufacturing environments, oil rigs, and autonomous systems, where network latency prevents real-time decision-making. Applications requiring response times of 10 milliseconds or below cannot tolerate the inherent delays of cloud-based processing.
Resilience requirements: Mission-critical tasks that cannot be interrupted require on-premises infrastructure as either primary compute or backup systems in case connection to the cloud is interrupted.
Intellectual property protection: Because the majority of enterprises’ data still resides on premises, organizations increasingly prefer bringing AI capabilities to their data rather than moving sensitive information to external AI services. This allows them to maintain control over intellectual property and meet compliance requirements.
Due in part to these factors, companies in many countries are rolling out new data center capacity at an unprecedented rate. Danish property management firm Thylander is building out new data center colocations within the Nordic country, providing the rack space, networking, power, and cooling that cutting-edge graphics processing units (GPUs) and other hardware used in AI workloads require.
Anders Mathiesen, CEO of Thylander Data Centers, says all the hyperscale-sized data centers currently in Demark are owned by foreign companies. But there are growing calls from businesses for more options that will allow their data to be stored and processed by companies owned and operated within the country.
“Looking at data sovereignty and thinking about who actually owns data centers was the start of us saying that we want to do something Danish for Danish companies, but also for external [companies] who think the Danish markets are valuable,” Mathiesen says.6
The infrastructure mismatch
While enterprises can use these factors to guide future moves, the current state of their infrastructure may create other barriers. Existing data centers feature raised floors, standard cooling systems, orchestration based on private cloud virtualization, and traditional workload management, all designed for rack-mounted, air-cooled servers. The technical specifications of AI infrastructure—from networking requirements between GPUs to advanced interconnecting technologies like InfiniBand—demand architectural approaches that don’t exist in traditional enterprise environments.
The AI-optimized data center
Rather than choosing between cloud and on-premises infrastructure, leading enterprises are building hybrid architectures that leverage the strengths of each platform. This approach is a shift from the binary cloud-versus-on-premises thinking that dominated the previous decade.
This physical infrastructure mismatch could become a primary bottleneck as enterprises expand AI adoption. However, forward-looking organizations are beginning to explore the contours of the data center of the future.
The three-tier hybrid approach
Leading organizations are implementing three-tier hybrid architectures that leverage the strengths of all available infrastructure options.
Cloud for elasticity: Public cloud handles variable training workloads, burst capacity needs, experimentation phases, and scenarios where existing data gravity makes cloud deployment a logical choice. Hyperscalers provide access to cutting-edge AI services, simplifying the management of rapidly evolving model architectures.
On-premises for consistency: Private infrastructure runs production inference at predictable costs for high-volume, continuous workloads. Organizations gain control over performance, security, and cost management while building internal expertise in AI infrastructure management.
Edge for immediacy: Local processing handles time-critical decisions with minimal latency, particularly crucial for manufacturing and autonomous systems where split-second response times determine operational success or failure.
“Cloud makes sense for certain things. It’s like the ‘easy button’ for AI,” says AI thought leader David Linthicum. “But it’s really about picking the right tool for the job. Companies are building systems across diverse, heterogeneous platforms, choosing whatever provides the best cost optimization. Sometimes it’s the cloud, sometimes it’s on-premises, and sometimes it’s the edge.”7 (See sidebar for the full Q&A.)
Hybrid reality check: David Linthicum on right-sizing AI infrastructure
Dave Linthicum is a globally recognized thought leader, innovator, and influencer in AI, cloud computing, and cybersecurity. He provides thought leadership, architecture, and technology guidance to Global 2000 companies, new innovative companies, and government agencies.
Q: As enterprises evolve from cloud-first to hybrid models, what challenges will they face and what are the solutions?
A: The biggest challenge is complexity. When you adopt heterogeneous platforms, you’re suddenly managing all these different platforms while trying to keep everything running reliably. We saw this happen with multicloud adoption: Companies went from managing 5,000 cloud services to 10,000 services overnight, and they had to run and operate all of that across different platforms.
Rather than managing each platform individually, enterprises need unified management approaches. I don’t want to have to think about how my mobile platform stores data differently than my cloud environment or my desktop. You need to push all that complexity down to another abstraction layer where you’re managing resources as groups or clusters, regardless of where they physically run.
Otherwise, enterprises handle complexity by hiring specialized teams and buying platform-specific tools. That’s expensive and inefficient, and it drains business value because you’re scaling complexity management through ad hoc processes instead of thinking strategically. It’s really about reducing that operational headache so you can focus on what actually matters to your business.
Q: Deloitte research suggests that when cloud costs reach 60% to 70% of equivalent hardware costs, enterprises should seriously evaluate alternatives. What other tipping points should enterprises monitor when considering the shift from cloud-first to hybrid models?
A: All things being equal between on-premises infrastructure and public cloud, I’m going with public cloud every time because it’s easier and gives me scalability and elasticity. But when cloud costs reach 60% to 70% of equivalent hardware costs, you should evaluate alternatives like colocation providers and managed service providers. That’s a practical, quantifiable metric that can help you make data-driven choices about infrastructure deployment rather than defaulting to cloud-first strategies regardless of economic considerations.
Q: How does the problem of data center sustainability get solved?
A: At the end of the day, we’re not going to stop data center growth. The appetite is huge. I live in Northern Virginia—there are a hundred data centers within 10 miles of where I’m sitting right now. So if we’re going to move in that direction, let’s try to do less damage by using clean power sources. Nuclear is one of them. That’s scary for a lot of people, but there aren’t any other options.
I think we’ll see small nuclear power plants in data-center-concentrated areas, and everybody’s going to pull power off those just like they do now. There’s a power plant near me that does nothing but serve data centers—but it’s not clean energy. Doing the same thing with more environmentally friendly options while still letting us sustain the business is really the only trade-off we’re going to get. We can’t increase the grid at any kind of speed that makes it worth the while unless we figure out some sort of power source.
Q: Do you have a hot take on this topic, or a piece of conventional wisdom that you think is wrong?
A: That’s easy. Not everything is going to run on GPUs, and we need to get out of that mindset. The GPU hoarding a few years ago was just ridiculous. The reality is that most workloads using AI in ways that actually bring value back to enterprises aren’t going to need specialized processors. They’re going to run perfectly fine on CPUs. Now, if I’m doing an LLM and huge amounts of training, then yeah, I need specialized processors or else it’s going to take 10 years instead of a few months. But those use cases are very few and far between. Most enterprises aren’t going to be doing that level of AI work.
Decision framework for compute infrastructure placement
A framework for making compute infrastructure decisions (figure 1) may seem straightforward, but such choices are rarely simple in practice. Everyone wants the fastest hardware running the latest models with the fewest barriers to getting their projects up and running, but this can get expensive.
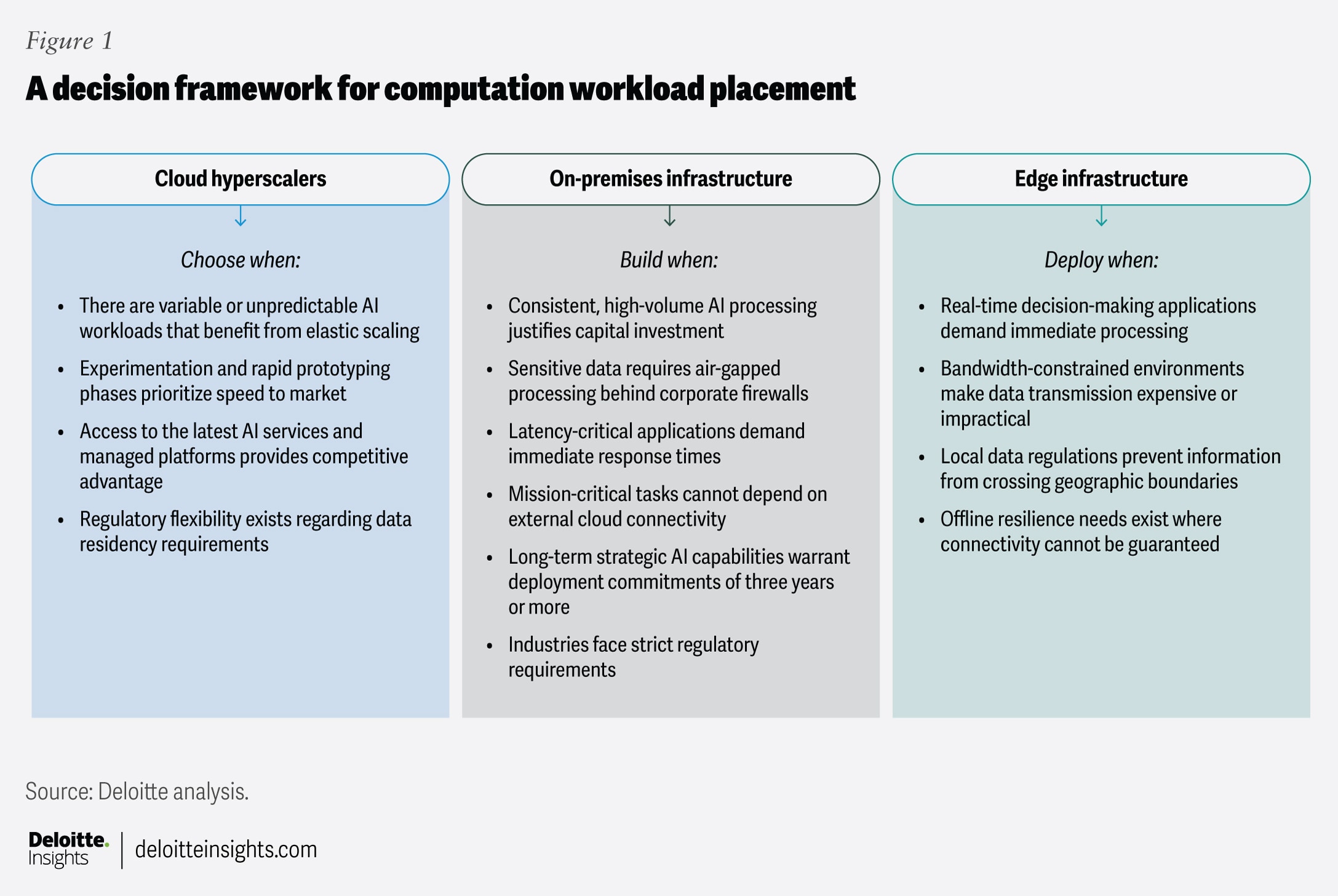
That’s why Dell Technologies recently created an architecture review board. This board evaluates new AI projects and ensures they use consistent tools and the optimal infrastructure based on cost, performance, governance, and risks. Dell is currently developing agentic AI use cases across its four core areas, and leaders are looking to expand use cases within these high-ROI areas. As the number of projects grows, leaders say it’s critical to ensure they run on appropriate infrastructure. Sometimes that may mean calls to an AI service provider’s API, but in other cases it means using entirely on-premises resources.
“Having that architectural rigor is even more necessary now that the resource intensity of these systems is so high,” says John Roese, global chief technology and chief AI officer at Dell. “When you start talking about things like reasoning models and agents, and the costs associated with them, having that architectural discipline is critical.”8 (See sidebar for the full Q&A.)
The hardware architecture revolution
This moment presents enterprises with an unprecedented opportunity to move beyond thinking centered on central processing units (CPUs) toward specialized AI-optimized hardware architectures. Organizations are making deliberate decisions about processor deployment, transitioning from general-purpose computing to workload-specific optimization.
The evolution involves integrating multiple processor types within single systems: GPUs for parallel AI processing, CPUs for orchestration and traditional workloads, neural processing units for efficient inference, and tensor processing units for specific machine learning tasks. Server refreshes now include mixed CPU/GPU configurations. Where once server racks might have had four to eight GPUs on a tray with a CPU coordinator, we’re increasingly seeing two GPUs per CPU.
The custom-built AI data center: These trends are coalescing into what we might call the AI data center, which involves a higher number of GPUs relative to CPUs; new server models and orchestration layers for hybrid workloads; evolving data-center form factors that allow for rapid deployment; optical networking between processors for reduced latency; and migration and replatforming of workloads to leverage GPU capabilities.
The rise of AI factories
AI workloads are driving the emergence of “AI factories”: integrated infrastructure ecosystems specifically designed for artificial intelligence processing. These environments integrate multiple specialized components into a single solution:
- AI-specific processors: GPUs co-packaged with high-bandwidth memory and specially designed CPUs optimized for AI orchestration rather than general computing tasks
- Advanced data pipelines: Specialized systems for gathering, cleaning, and preparing data specifically for AI model consumption, eliminating traditional extract, transform, load bottlenecks
- High-performance networking: Advanced interconnection technologies to minimize data-transfer latency, including optical networking advancements and specialized GPU-to-GPU communication protocol
- Algorithm libraries: Preoptimized software frameworks that align AI functionality with specific business objectives, reducing development time and improving performance
- Orchestration platforms: Unified management systems capable of handling multimodal AI workloads across different compute types, enabling seamless integration between various AI technologies
These AI factories can also offer excess computing capacity through service models, allowing organizations to monetize unused processing power while maintaining strategic control over critical workloads.
The greenfield advantage: John Roese on purpose-built AI infrastructure
John Roese is global chief technology officer and chief AI officer at Dell Technologies, where he leads the company’s global technology strategy and AI transformation initiatives. With decades of experience in enterprise technology, he focuses on driving practical AI implementation that delivers measurable business value while maintaining rigorous governance and security standards.
Q: What are the biggest bottlenecks and challenges related to AI infrastructure?
A: The infrastructure many enterprises have today was designed for the pre-AI era and based on an architectural decision made when the multicloud era began. Businesses made these decisions—like which cloud to use, the topology, what to do on-prem versus off-prem—probably before the pandemic. No one is that smart or lucky to have designed their architecture for a thing that didn’t exist when they designed it.
Very quickly, most of the infrastructure capacity will be in service of AI systems, not traditional workloads. AI workloads need accelerated compute; they need a knowledge layer, not just data. These workloads are distributable, and they’re in a high-entropy industry with lots of different approaches. That’s an entirely different type of workload at the most foundational infrastructure levels.
Q: How does the concept of AI factories figure into this?
A: AI factories are greenfield environments for AI. Retrofitting a brownfield environment designed for traditional enterprise applications and services to properly run an AI environment is difficult. You need an accelerated computing architecture, often not just CPUs [central processing units]. The topology from a networking perspective is simplified, but very high-speed. The storage environment is really a knowledge layer: vector databases, graph databases, knowledge graphs, context-aware chatbots, and data pipelines. And the actual AI applications and their environments are mostly extremely modern.
You could try to retrofit that into your brownfield infrastructure but we recommend building an optimized infrastructure for AI: an AI factory. That will allow you to move much faster, de-risk your architecture, and create an environment purpose-built for AI.
Q: How long does it typically take to spin that up?
A: It’s actually faster than the retrofitting. We’ve stood up parallel environments with GPUs and knowledge layers attached to the rest of the infrastructure. A data mesh connects all data together. The AI tools talk to the same data mesh that traditional tools talk to, but the actual physical topology—the infrastructure they live on—is accelerated servers, knowledge layer data management, AI workloads, observability, and controls.
Standing that up as a separate entity was faster than trying to retrofit the existing environment. You can buy an appliance that’s basically a collection of storage, computing, and networking preassembled to run the whole agentic AI stack out of the box. By standing it up outside the brownfield, you’re able to isolate it from a lot of the complexity, which allows you to move fast.
This might sound like an extra cost, but it really isn’t. The operational expense of trying to weave AI capabilities into your existing legacy environment would likely be higher than building a new, dedicated infrastructure.
Q: How does sustainability play into the infrastructure decision-making process?
A: Energy efficiency is a key consideration in the planning process. Innovations in advanced cooling systems, thermal management solutions, and servers can maximize performance per watt while empowering organizations to monitor and reduce their energy use.
One of the biggest choices you have is when to use liquid cooling approaches. For example, direct liquid cooling can be at least twice as energy-efficient as free air cooling, so a single rack with direct liquid cooling can help reduce costs and footprints.
Second, focus on your legacy infrastructure. Poor utilization of IT assets is the largest cause of energy waste in data centers. If you can optimize your legacy infrastructure to reduce waste and increase efficiency, you may be able to reduce the incremental environmental impact of your AI expansion.
Finally, much of the AI workload can be pushed to the client device. An AI PC is a very energy-efficient, distributed computing environment. It’s already in the energy grid and exists within your environmental footprint. A significant amount of computing tasks could be moved out of the data center and onto that device. Depending on workload needs, if you distribute parts of the functionality out to these highly efficient AI PCs, you could reduce your overall footprint.
The new frontiers of the data center
The current transformation in AI infrastructure represents only the beginning of a broader computational revolution. Over the next five to 20 years, as emerging computing paradigms mature, data centers will need to continue to evolve to accommodate increasingly specialized tools for specific applications.
Infrastructure evolution continues
Custom silicon integration is accelerating beyond general-purpose chips toward specialized processors designed for specific AI tasks. This includes neuromorphic computing for pattern recognition applications9 and optical computing for more energy-efficient data processing, which is an increasing focus for AI.10
Quantum computing integration is likely to fundamentally alter data-center design requirements once the technology achieves scale.11 Quantum systems demand specialized infrastructure, including cooling systems, advanced form factors, and extreme noise and temperature sensitivity controls that differ dramatically from current AI infrastructure needs.
Managing this hybrid architecture requires new categories of expertise and management tools. Future orchestration layers may replace legacy solutions with platforms specifically designed for AI workloads. These systems may manage not only traditional virtual machines and containers but also quantum processing units, neuromorphic chips, and optical computing arrays.
Workforce transformation requirements
The infrastructure transformation may require reskilling across IT organizations. Data center teams will likely have to transition from traditional server management to AI-optimized infrastructure operations, GPU cluster management, high-bandwidth networking, and specialized cooling systems.
Network architects face the challenge of designing for AI-first traffic patterns and high-throughput requirements that differ fundamentally from traditional enterprise networking. The networking demands of AI—including GPU-to-GPU communication, massive data-transfer requirements, and ultra-low latency needs—require expertise that many organizations lack.
Cost engineers will need to develop expertise in hybrid compute portfolio optimization, understanding not just cloud economics but also the complex trade-offs between different infrastructure approaches. This includes mastering new financial models that account for GPU utilization rates, inference economics, and hybrid cost structures.
After years of cloud migration have eliminated much internal data center expertise, many organizations struggle to find professionals who understand AI infrastructure requirements. This talent gap represents both a challenge, particularly for businesses that have shifted completely to the cloud, and an opportunity for organizations willing to invest in workforce development.
AI agents managing AI infrastructure
With the growing complexity of AI infrastructure, traditional IT playbooks are likely inadequate for the dynamic optimization required by AI workloads, leading to the emergence of custom-designed AI copilots for IT operations that can summarize alerts, propose root causes, and suggest remediation strategies.12
These agents are extending into capacity planning and vendor selection, with services like Amazon Web Services publishing AI patterns that auto-analyze capacity reservations and recommend actions through Amazon Bedrock agents.13 This represents the precursor to fully autonomous agents that should be able to dynamically juggle model selection, instance-type optimization, spot versus reserved pricing, and multicloud cost and carbon optimization.
Procurement is becoming algorithmic and continuous rather than periodic and manual. Organizations are likely to increasingly rely on AI agents to make real-time infrastructure decisions based on workload demands, cost fluctuations, and performance requirements.
Sustainable data center innovation
The environmental impact of AI infrastructure is driving innovation in sustainable computing approaches. Government and private sector initiatives are exploring nuclear energy to power data centers without carbon emissions, though implementation remains limited to hyperscalers and organizations with substantial capital resources.
Microsoft’s Project Natick demonstrated that underwater data center containers could provide practical and reliable computing while using ocean water as a heat sink, though the company ended the research program after completing a concept phase.14 In contrast, Chinese maritime equipment company Highlander has deployed commercial underwater data center modules and is expanding operations with formal government backing.15
Renewable energy integration is accelerating with projects like Data City in Texas, which plans fully renewable energy-powered data center operations with future hydrogen integration capabilities.16 These initiatives point toward broader trends in sustainable computing infrastructure.
Emerging concepts include orbital data centers that operate on solar power and radiate heat directly into space, eliminating the need for cooling water entirely. Companies are developing on-orbit compute capabilities, with some achieving early flight tests of lunar data center payloads.17
The computation renaissance: AI infrastructure as strategic differentiator
The organizations that successfully navigate this infrastructure transformation are likely to gain sustainable competitive advantages in AI deployment and operation. Those that fail to adapt are likely to face escalating costs, performance limitations, and strategic vulnerabilities as AI becomes increasingly central to business operations.
This AI infrastructure transformation is more than a temporary market adjustment; it’s a fundamental shift in how enterprises approach computing resources. Just as cloud computing reshaped IT strategy over the past decade, hybrid AI infrastructure will probably define technology decision-making for the decade ahead.
The computation renaissance has begun, and its outcomes will determine which organizations thrive in an AI-driven business environment.
by
Nicholas Merizzi
Chris Thomas
Ed Burns
The authors would like to thank executive sponsor Bill Briggs, as well as the Office of the CTO Tech Market Presence team, without whom this report would not be possible: Caroline Brown, Preetha Devan, Bri Henley, Dana Kublin, Makarand Kukade, Haley Gove Lamb, Heidi Morrow, Sarah Mortier, Abria Perry, Catarina Pires, and Kelly Raskovich.
Much gratitude goes to the many subject matter leaders across Deloitte who contributed to our research for the Computation chapter: Bernhard Lorentz, Baris Sarer, Duncan Stewart, and Rohit Tandon.
Additionally, the authors would like to acknowledge and thank Katarina Alaupovic, Allison Cizowski, Deanna Gorecki, Ben Hebbe, Mikaeli Robinson, and Madelyn Scott; Amanpreet Arora and Nidhi John; as well as the Deloitte Insights team, the Marketing Excellence team, the NExT team, and the Knowledge Services team.
Cover image by: Jim Slatton; Getty Images, Adobe Stock