
Adapting Model Validation in the Age of AI
Refining Principles and Developing Tools for Effective Validation amid Rising Concerns
The rapid advance of artificial intelligence (AI) in general and Large Language Models (LLMs) in particular is making quality assurance and validation of models a hot topic. Validation is becoming particularly important for LLMs as problems, such as memorisation of training data, encoding of bias and generation of inappropriate content are causing both regulators and the public to press for controls on AI and LLMs. This blog looks at the key issues and indicates possible ways forward for AI model validation by refining principles and developing tools.
Faster learning in a faster world
One hundred million active users. It took Instagram two and half years, TikTok nine months, but ChatGPT reached the landmark in only two months. In the process, OpenAI’s ChatGPT has become the best-known, but by no means the only, LLM. Beyond ChatGPT, the wider adoption of LLMs such as Google’s Bard and StabilityAI’s StableLM appear to indicate a tipping-point in the ubiquity of AI and natural language processing. With their ability to reveal new insights, LLMs seem to be affecting every area of our lives at break-neck speed. But what are the implications for finance employers and employees of the capabilities and speed of adoption of this technology? To make the best possible decisions in an increasingly complex world it is vital to ensure continuous evolution of approaches and methods for validating and providing quality assurance on LLMs (in particular) and AI more widely. In this blog we focus on the single, but what many of our clients tell us is the critical issue, of whether LLMs have kickstarted an AI revolution in finance in the vital domain of model validation.
Figure 1: Five key elements of validation and quality assurance for AI models
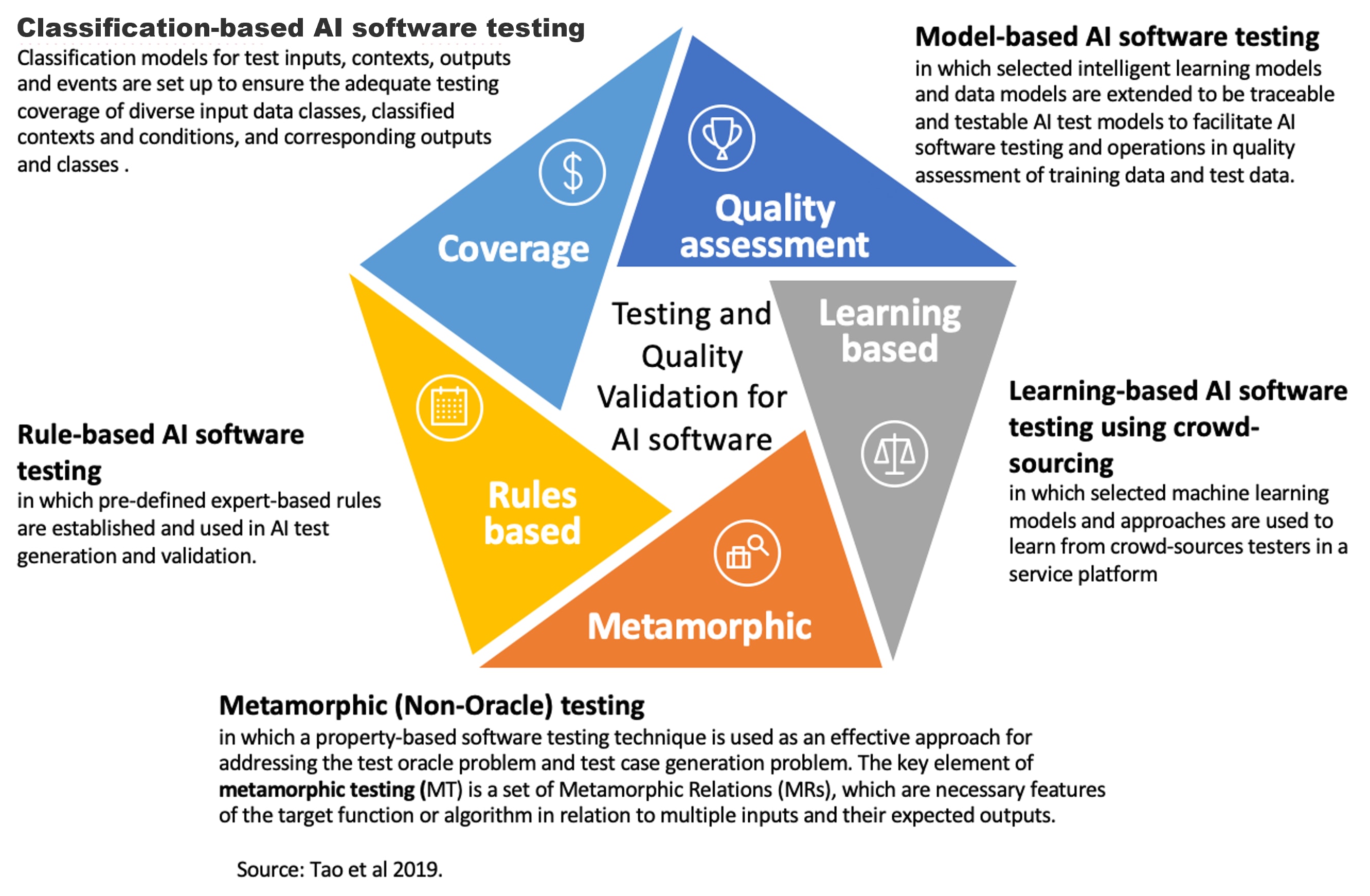{kind=link}
Whilst high-level languages like R and Python have become the standard for AI model development, care needs to be taken to ensure that internally consistent, correct, non-contaminating validation testing is carried out – a task which can be complex and time consuming. Validation schemes such as hold-out sets and cross-validation are vital if models are to be thoroughly and reliably quality assured. From a practical perspective, such validation techniques need to be modular so that what happens inside the procedures such as cross-validation can be applied consistently, minimising the likelihood of problems such as contamination and bias. One of the best approaches for achieving this is applying validation methods that support multiple levels of validation so that they can be nested one level inside another, thereby minimising potential weaknesses in the validation process. A further important function of validation techniques like cross-validation is to prevent overfitting, where the machine learning model gives accurate predictions for one dataset but not for another.
Develop Tools
The good news from the validation perspective is that there have been extensive public and private resources devoted to testing LLMs. One example is the BIG-bench3 AI validation tool, which currently consists of 204 tasks, contributed by 450 authors across 132 institutions. Unfortunately, despite the impressive statistics tests have generally been written and added in an ad-hoc fashion, whereby test users add tasks by extending the existing BIG-bench code or supplying template parameters for that code. In such an approach, it is up to the user to convert the expected LLM behaviour into a sequence of test vectors that can be executed, making it difficult to maintain, modify or extend test functionality.
An alternative approach by Kuchnik et al4, is a novel LLM validation tool called ReLM. The approach uses regular expressions, which are sequences of characters that specify match patterns in a longer series of text. ReLM is the first queryable test interface for LLMs and is a Regular expression engine for Language Models that enables identification of commonly occurring patterns (in the form of sets of strings), with standard regular expressions. ReLM is the first system capable of expressing a query as a complete set of test patterns. This enables both developers and validators to explain and measure LLM behaviour directly over datasets that would otherwise be too large to enumerate.
Where Next?
The reasonably good news for teams validating AI models is that computing power continues to increase almost in-line with Moore’s law5, which provides help with data transformation, training, testing, model optimisation and validation. Further good news is the increased research output in the key domains of mathematics and algorithm design, much of which is being targeted towards improving the efficiency, accuracy and robustness of AI models. The further good news is that the emergence and ongoing improvement in testing tools such as BIG-bench and ReLM provides a vital infrastructure to enable validators to begin to modify their approaches to keep pace with the rapid pace of development in AI.
However, increased focus needs to be brought to bear on further development of validation principles to ensure that conceptual framework that continues to emerge remains fit for purpose. A key element here will be to ensure that crowd-sourcing of learning-based AI software does not become contaminated by the increasing appearance of training and testing data, as well as synthetically generated data. Arguably, a key reason behind the difficulty in validation is that most AI models are black boxes. As we may not know what happens inside such black boxes, it is hard to validate whether each computational step is fully understood and under control. This suggests that an alternative direction to improve ease of validation is to develop more interpretable models as they provide explanations for their responses. Therefore, in addition to defining test sets to see if the responses meet the expectations, it is possible to validate whether the response is produced following reasonable logic.
A final thought concerns whether employers and employees, developers and validators alike, will be able to keep pace with the increasingly rapid development and deployment of ever-more sophisticated AI models and applications. A recent example of this speed and spread of change in AI occurred when Meta launched Threads, its challenger to Twitter, which gained 10 million users in just seven hours.

